
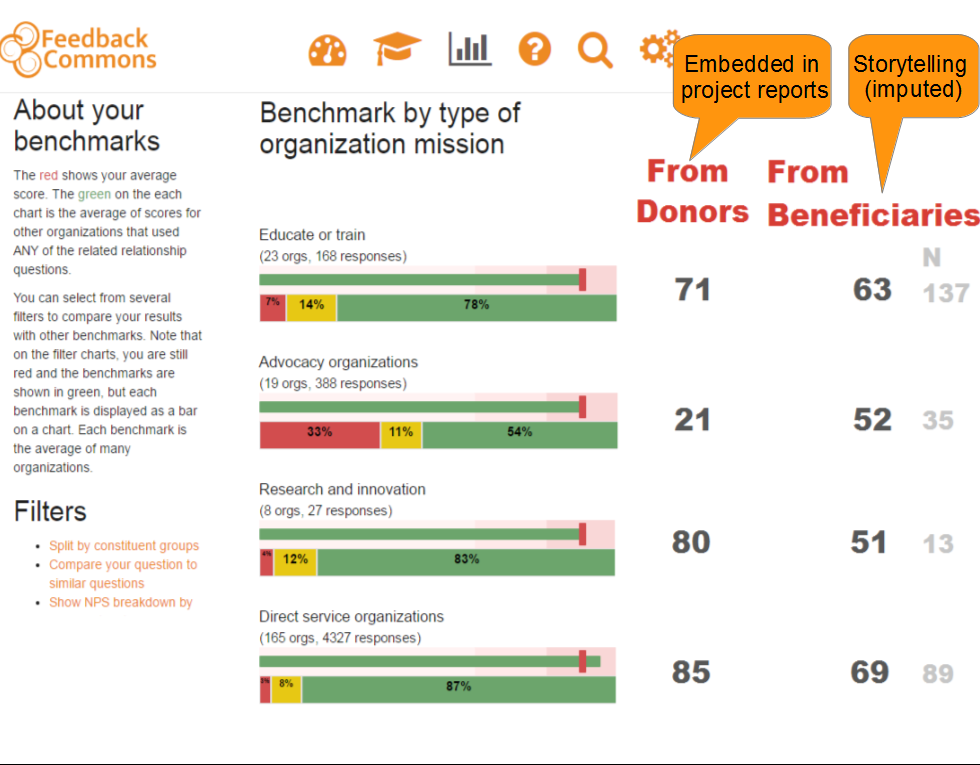
Using net promoter to get a better perspective about non-profit work

First 3 months of Images and Memes from Ukraine Russia War

2021 memes and images

The Church Religion Spectrum

Year of the covid: 2020 memes and images
Andy Slavitt’s public #Covid19 response journal (March 14 through May 26, 2020)

The Coronavirus message we should have heard from President Trump

